

Il contributo che segue nasce in larga parte dall’intervento del prof. Luigi Portinale alle XVIII Giornate Primaverili di Medicina Interna, tenutesi il 5 aprile 2025 presso l’Ospedale S. Croce di Cuneo. Il convegno, dal titolo “Medicina clinica e intelligenza artificiale: fondamenti, applicazioni e riflessioni etiche”, ha rappresentato un momento di approfondimento e confronto di grande rilievo, coinvolgendo clinici, ricercatori e filosofi del settore.
L’iniziativa, promossa e presieduta dal prof. Luigi Fenoglio, direttore della Struttura Complessa di Medicina Interna dell’Ospedale S. Croce e Carle, ha offerto un’occasione concreta per analizzare – con rigore scientifico e sensibilità clinica – le opportunità e i limiti dell’intelligenza artificiale in ambito medico. L’articolo che segue accompagna il lettore in un percorso chiaro e documentato attraverso l’evoluzione dell’IA, il suo impatto sulla pratica clinica e le sfide aperte sul piano etico e culturale. Se ne consiglia la lettura guardando sempre ai box esplicativi di riferimento per una miglior comprensione.
L’intelligenza artificiale (IA) è sempre più presente anche nella pratica clinica quotidiana. entrata con forza nel dibattito medico, sociale e politico, spesso tra entusiasmi e timori. . Non si tratta più solo di tecnologie riservate alla radiologia o alla medicina specialistica. Già oggi, l’IA può aiutare il medico a gestire i dati clinici, interpretare esami, proporre diagnosi differenziali e persino spiegare in modo semplice le malattie ai pazienti. Nel contesto sanitario dove i tempi sono sempre piu’ limitati e le decisioni cliniche devono essere rapide ed accurate, l’IA può fornire un valido supporto: dalla gestione automatica dei dati clinici, all’identificazione precoce di pazienti a rischio, alla spiegazione semplice di diagnosi e terapie ai pazienti. Per comprendere meglio cosa sia e che cosa possa fare, è necessario partire da una riflessione storica, concettuale e tecnica, a cominciare da una domanda: possono le macchine pensare?
Dalle origini logiche all’intelligenza artificiale
Già Aristotele aveva gettato le basi del ragionamento deduttivo attraverso i sillogismi: partire da premesse note per giungere a conclusioni nuove. Da questo principio la storia della logica e della matematica ha portato, nei primi anni ’50, al pensiero visionario di Alan Turing che formulò il celebre “Imitation Game” (oggi noto come test di Turing): un sistema può essere considerato intelligente se, dialogando con un essere umano, quest’ultimo non riesce a distinguerlo da un altro interlocutore umano.
La definizione “intelligenza artificiale” venne introdotta nel 1955 durante il seminario di Dartmouth (McCarthy et al. 1955) per descrivere la visione di sistemi capaci di simulare funzioni cognitive, da allora sono succeduti studi e ricerche, entusiasmi e delusioni approcciati oggi a vere e proprie rivoluzioni (vedi Box.1).
Intelligenza, apprendimento e specializzazione
L’IA è una branca dell’informatica che studia sistemi in grado di svolgere attività che, richiedono una elaborazione logica dei dati e quindi una “intelligenza” di sistema: riconoscere immagini, comprendere il linguaggio, prendere decisioni, imparare da nuove informazioni.
Ma cosa si intende concretamente per “intelligenza”? E quali compiti dovrebbe svolgere un’IA? A questa domanda si risponde con due ipotesi che nascono dalla visione di IA come un insieme di tecniche che permettono alle macchine di svolgere compiti che richiederebbero intelligenza umana. In medicina, questo significa analizzare dati clinici, formulare ipotesi diagnostiche, prevedere rischi o suggerire terapie.
- IA forte (Strong AI): è la forma cui mira l’evoluzione tecnologica proponendosi di imitare completamente i processi della mente umana, compresi processi di coscienza, comprensione semantica e intenzionalità. Questa visione filosofica oltre che tecnica, spesso legata alla scienza cognitiva e alla neuroinformatica, pur teoricamente affascinante, rimane obiettivo lontano e controverso, sia per limiti computazionali sia per implicazioni etiche e ontologiche (Searle 1980).
- IA debole (Weak AI): la forma attualmente in uso, specializzata in compiti precisi (es lettura ECG o analisi di esami radiografici) si concentra su sistemi progettati per risolvere compiti specifici, spesso con prestazioni superiori a quelle umane in domini circoscritti. Questi sistemi non pretendono di “comprendere”, ma elaborano dati secondo regole statistiche, apprendendo da esempi passati. È il paradigma dominante nell’IA contemporanea, largamente impiegato in medicina, industria, finanza e linguistica computazionale (Russell and Norvig 2016).
- L’IA debole ha già dimostrato una grande utilità nel contesto clinico ad esempio:
- nella diagnostica per immagini, dove modelli addestrati su migliaia di TAC o RM riescono a individuare lesioni millimetriche con sensibilità elevata;
- nell’analisi elettrocardiografica automatica, dove reti neurali interpretano segnali ECG e classificano aritmie con performance comparabili a quelle di cardiologi esperti (Hannun et al. 2019);
- nei sistemi di supporto alla decisione clinica (CDSS), che integrano dati anamnestici, di laboratorio e farmacologici per suggerire diagnosi o strategie terapeutiche personalizzate.
Machine learning: apprendimento dai dati
Il passaggio storico e concettuale più importante dopo Dartmouth è rappresentato dall’introduzione del machine learning (ML) ovvero la macchina che “impara” dai dati. Coniato da Arthur Samuel nel 195 9(Samuel 1959), il termine indica l’abilità di sistemi che apprendono senza essere programmati esplicitamente, ma semplicemente analizzando grandi quantità di dati.
Questo passaggio chiave ha permesso di creare modelli che aiutano a fare diagnosi e si aggiornano in tempo reale, adattandosi ai cambiamenti.
Punto di forza del machine learning (ML) rispetto ai sistemi basati su regole fisse è la flessibilità: l’algoritmo non si basa su istruzioni rigide, ma impara osservando i dati. Se qualcosa cambia – ad esempio emergono nuove varianti di virus o si scoprono nuovi biomarcatori – il sistema è in grado di aggiornarsi da solo, senza bisogno di un programmatore che lo riscriva ogni volta.
In questa capacità di adattarsi all’incertezza e alla variabilità – che in medicina sono all’ordine del giorno – si trova il cuore dell’intelligenza artificiale moderna applicata in ambito clinico.
Esempio pratico:
- Si forniscono al sistema migliaia di ECG già interpretati.
- Il sistema impara a riconoscere le caratteristiche delle aritmie.
- Alla fine, riesce a leggere un nuovo ECG con un buon livello di accuratezza.
La svolta probabilistica: la logica bayesiana e ragionamento in condizioni di incertezza
A partire dagli anni ’80, lo studioso Judea Pearl (Pearl 2014) ha dato una forma teorica a un nuovo modo di ragionare, introducendo i cosiddetti modelli probabilistici bayesiani (Vedi Box.2).
Questi modelli, chiamati anche reti bayesiane, permettono di rappresentare i legami tra causa ed effetto anche quando i dati sono incompleti o incerti (situazione assai comune nella pratica clinica).
Rispetto ai vecchi sistemi esperti, basati su regole rigide, i modelli bayesiani più flessibili: permettono di valutare diverse ipotesi possibili, aggiornare le conclusioni man mano che arrivano nuovi dati, e stimare le probabilità a partire da quanto già si conosce.
In medicina, questo approccio permette di unire anamnesi, sintomi e risultati di laboratorio in una valutazione che somiglia di più al ragionamento clinico del medico ed è supportata da calcoli probabilistici. (Vedi Box.2)
Reti neurali e deep learning: come apprendono le macchine
Nel 2016, quando il sistema AlphaGo di DeepMind è riuscito a sconfiggere il campione mondiale di Go combinando reti neurali profonde con tecniche di apprendimento per rinforzo, migliorando le proprie prestazioni attraverso il gioco autonomo contro sé stesso, si verifica uno dei primi esempi concreti di apprendimento ‘superumano’ in un contesto complesso (Silver et al. 2016).
Deep learning: reti neurali e apprendimento profondo
Il salto di qualità recente è connesso al “deep learning”, la branca del machine learning che utilizza reti neurali artificiali profondamente stratificate (vedi Box.3 e Fig.1) in sistemi sofisticati che impiegano reti neurali artificiali ispirate al funzionamento del cervello umano: più dati si ricevono, più l’IA affina le proprie capacità.
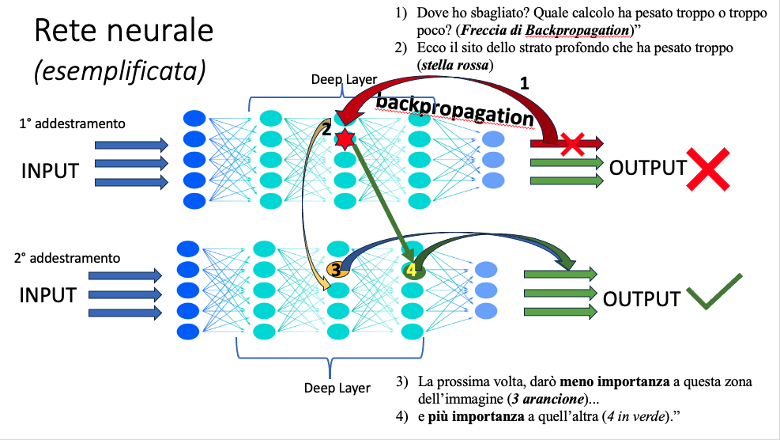
Fig.1 esemplificazione di rete neurale (vedi Box.3)
Determinante per i risultati conseguiti dall’IA è stato anche il modello AlexNet (Krizhevsky, Sutskever e Hinton 2012) sistema che – presentato nel 2012 e capace di riconoscere e classificare milioni di immagini contenute nel vastissimo database ImageNet – raggiungesse un livello di precisione senza precedenti.
La disponibilità di grandi quantità di dati e l’uso di processori molto potenti chiamati GPU (Graphics Processing Unit) combinata alle reti neurali profonde (modelli ispirati al funzionamento del cervello umano) sono divenuti risorse efficaci in compiti complessi come il riconoscimento delle immagini, superando i metodi tradizionali.
Le GPU, a differenza delle CPU (Central Processing Unit), sono progettate per eseguire moltissimi calcoli contemporaneamente. Questo le rende perfette per gestire l’enorme quantità di informazioni che l’intelligenza artificiale richiede per “imparare” e fare previsioni.
Senza questo tipo di potenza di calcolo, l’IA moderna – come la conosciamo oggi – non sarebbe mai potuta nascere.
Questi modelli sono solo vagamente ispirati alla struttura del cervello umano: anziché riprodurne fedelmente l’anatomia o il funzionamento, ne mutuano l’idea di “neuroni” virtuali, connessi tra loro e organizzati in livelli. Ciascun neurone esegue semplici operazioni matematiche (come somme “ponderate” e funzioni di “attivazione”), ma il potere del modello deriva dalla combinazione gerarchica e dalla vastità dei dati su cui viene addestrato.
L’obiettivo di questi modelli è apprendere rappresentazioni complesse dei dati, come pattern visivi o strutture linguistiche, attraverso una fase di addestramento supervisionato o non supervisionato. Per esempio, se il modello riceve migliaia di radiografie etichettate come “normali” o “patologiche”, apprenderà a riconoscere correlazioni statistiche tra i pixel e le etichette. Dopo l’addestramento, può analizzare una nuova immagine e fornire una predizione basata sulle distribuzioni probabilistiche apprese. (Vedi esempio Box.4 e Fig.2)
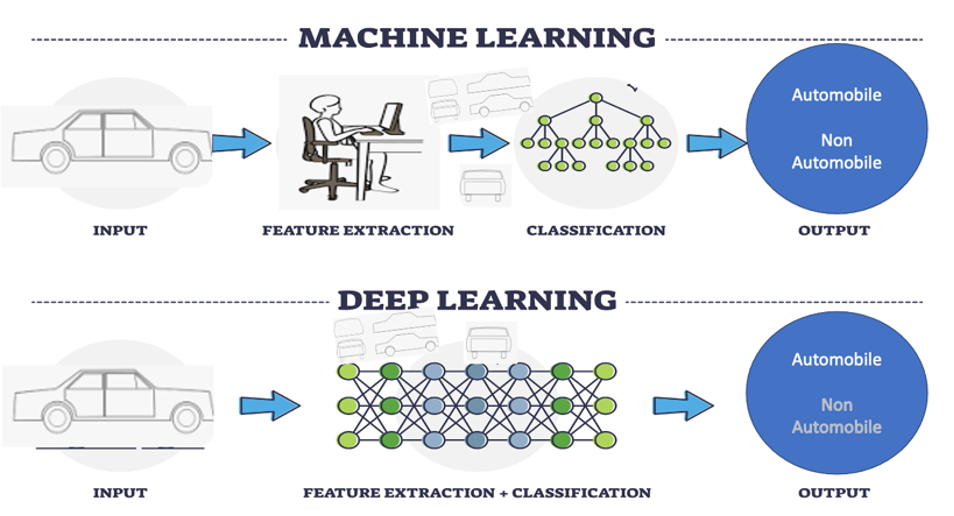
Fig.2 Cosa si intende modernamente per Machine learning e Deep learning (vedi Box.4)
L’apprendimento si basa sulla trasformazione di ogni elemento conoscitivo in token, ovvero unità di informazione (una parola, un suono, un pixel…), che vengono poi rappresentati come numeri, detti embedding.
Esempi di utilità pratica del Deep Learning per il medico:
- Supporto all’interpretazione di esami strumentali: ad esempio, lettura automatica di ECG, spirometrie o esami ematochimici.
- Sintesi e ricerca nelle cartelle cliniche: strumenti che aiutano a individuare parametri alterati, trend nei valori, o a sintetizzare le informazioni.
- Pre-screening e triage: chatbot o moduli automatici per la raccolta dei sintomi prima della visita.
- Educazione sanitaria del paziente: generazione di spiegazioni semplici e personalizzate delle diagnosi o delle terapie.
- Predizione del rischio: strumenti che, in base ai dati clinici, identificano pazienti a rischio di scompenso, diabete, eventi cardiovascolari.
La potenza e i limiti dell’IA generativa (vedi Box.5)
Oggi i cosiddetti foundation models (vedi Box.6), come ChatGPT (acronimo di Generative Pre-trained Transformer), Gemini o Claude, sono tra gli strumenti di intelligenza artificiale più avanzati e utilizzati.
Questi modelli riescono a generare testi, immagini, audio o video partendo da input minimi – chiamati prompt – cioè poche parole o istruzioni. Tuttavia, non ragionano davvero come un essere umano: funzionano facendo previsioni statistiche su cosa è più probabile che venga successivamente. Per esempio, scelgono la parola successiva in una frase, il pixel successivo in un’immagine o il suono successivo in un file audio. In altre parole funzionano attraverso predizioni sequenziali, ovvero predicono la sequenza più probabile, in base a quello che hanno ‘visto’ nei dati con cui sono stati addestrati (vedi Box.7). Infatti, tutti i dati (verbali, pixel, suoni) vengono trasformati in numeri, chiamati embedding, che servono a rappresentare parole o elementi visivi come punti in uno spazio matematico. Elementi con significati simili finiscono vicini tra loro in questo spazio, facilitando previsioni più coerenti (vedi Box.8)
Con l’evoluzione dei modelli linguistici a grandi dimensioni (Large Language Models: sistemi di IA progettati per comprendere e generare linguaggio umano), è emersa anche una nuova disciplina chiamata prompt engineering, che si occupa di progettare richieste (prompt) ottimali per ottenere le risposte desiderate dai modelli. Una delle tecniche più promettenti in questo ambito è il cosiddetto chain-of-thought prompting, che guida il modello a generare ragionamenti passo-passo, migliorando drasticamente le prestazioni in compiti logici e matematici (Sahoo et al. 2024) (vedi Box.9).
I modelli linguistici di grandi dimensioni (Large Language Models, LLMs) hanno conosciuto un’accelerazione vertiginosa a partire dal 2020 con l’introduzione di GPT-3 da parte di OpenAI. Grazie a un’architettura basata su centinaia di miliardi di parametri, GPT-3 ha mostrato un’abilità sorprendente nella generazione di testo coerente e rilevante. Il successivo modello, GPT-4, ha ampliato ulteriormente le capacità del predecessore, integrando anche input multimodali e raggiungendo risultati comparabili a quelli umani in diversi test accademici e professionali (OpenAI et al. 2024).
Questi modelli, detti appunto foundation models, sono addestrati su enormi quantità di dati testuali, visivi o sonori e apprendono a predire la continuazione più probabile di una sequenza. Per esempio, nel linguaggio naturale, il modello non “pensa” come un essere umano, ma calcola quale parola ha la maggiore probabilità di seguire la precedente, secondo le distribuzioni apprese durante l’addestramento.
È fondamentale sottolineare che questi modelli non possiedono una comprensione semantica o un modello causale del mondo: producono output coerenti grazie alla statistica predittiva, non grazie a un vero ragionamento. Questo spiega perché, ad esempio, un video generato può mostrare una persona che improvvisamente scompare: il modello ha prodotto fotogrammi plausibili isolatamente, ma senza coerenza temporale né nozione della persistenza degli oggetti. Perché questo? Perché la macchina non ha il concetto di persistenza: genera un fotogramma alla volta, senza “sapere” cosa c’era prima. È un’imitazione, non una comprensione.
Il loro funzionamento si basa sullo stesso concetto chiave: trasformare ogni informazione in numeri sotto forma di token e determinarne la più probabile successione. Quindi, attenzione: non ragionano, semplicemente calcolano la continuazione più probabile. Questa differenza è fondamentale.
Anche i modelli più avanzati, oggi, sono vulnerabili a input manipolati intenzionalmente. Gli attacchi adversariali sono perturbazioni minime, spesso invisibili all’occhio umano, applicate ai dati di input (ad esempio un’immagine) per ingannare l’algoritmo. Come dimostrato in uno studio celebre (Goodfellow, Shlens, and Szegedy 2015), un’immagine apparentemente normale di un panda può essere classificata erroneamente come una scimmia (un gibbone) semplicemente alterando pochi pixel (vedi fig. n. 4). Sono i cosiddetti attacchi adversariali, che dimostrano quanto questi sistemi, seppur potenti, siano fragili e manipolabili.

Fig.4 Poche interferenze possono portare fuori strada il sistema e un panda essere scambiato per un Gibbone (es. tratto da Goodfellow 2915) (Goodfellow, Shlens, and Szegedy 2015)
Quindi ad oggi, gli algoritmi IA hanno ancora difficoltà con il ragionamento causale. Una correlazione apparente – come quella tra vendite di gelati e incendi boschivi – può indurre il sistema a conclusioni prive di senso, ignorando variabili nascoste come la stagionalità.
Presente e futuro: tra promesse e responsabilità
Nonostante tutto, l’intelligenza artificiale sta già cambiando il mondo. Taxi a guida autonoma circolano oggi per le strade di San Francisco, senza conducente, gestiti tramite app. È un esempio concreto di una tecnologia che ha superato lo stadio della sperimentazione.
Tuttavia, come ha ricordato il prof. Portinale, è importante distinguere tra hype (cioè entusiasmo esagerato) e realtà. Le previsioni sensazionalistiche – come ad esempio l’obsolescenza dei radiologi entro il 2022 attribuita a Geoffrey Hinton nel 2015¹ – si sono dimostrate premature. Ma questo non significa che i cambiamenti non siano in corso: solo, vanno governati con lucidità e competenza.
“Il problema non è l’uomo contro la macchina”, ha concluso Portinale citando Pedro Domingos, “ma l’uomo contro un altro uomo che ha la macchina”.
In altre parole, sapere usare questi strumenti – comprenderli e saperli integrare – sarà la vera differenza. Non per sostituire l’intelligenza umana, ma per potenziarla con consapevolezza.
Rischi e limiti:
L’uso dell’intelligenza artificiale nella pratica clinica può offrire vantaggi concreti, ma comporta anche potenziali rischi che devono essere ben compresi nell’ambito sanitario. Un primo aspetto critico riguarda i dati su cui si basa l’apprendimento dell’IA: se questi dati non rappresentano adeguatamente la popolazione generale (ad esempio, includendo solo adulti giovani o persone di una certa etnia), l’output del sistema potrebbe risultare inaccurato o addirittura discriminatorio. Inoltre, i modelli di IA non si aggiornano automaticamente con l’evoluzione delle linee guida cliniche. Questo significa che un algoritmo addestrato anni fa potrebbe fornire suggerimenti obsoleti se non viene aggiornato regolarmente. Un ulteriore limite è legato alla trasparenza: alcuni sistemi producono risultati che appaiono convincenti ma il cui ragionamento interno è difficilmente interpretabile anche da esperti (il cosiddetto “black box problem”). Ciò rende difficile identificare e correggere eventuali errori, aumentando il rischio di sovrastima dell’affidabilità da parte dell’utente. Infine, va sottolineato che l’utilizzo dell’IA non solleva il medico dalla responsabilità clinica: la decisione finale resta umana. L’IA deve essere vista come uno strumento di supporto, mai come un sostituto del giudizio professionale.
Box.1 – 1956: la nascita ufficiale dell’Intelligenza Artificiale a Dartmouth College, New Hampshire (USA)
Durante una conferenza di ricerca di otto settimane, un gruppo di scienziati propone una nuova idea rivoluzionaria:
Ogni aspetto dell’apprendimento o qualsiasi altra caratteristica dell’intelligenza può, in linea di principio, essere descritto così precisamente da poter essere simulato da una macchina.
⇒ Questo è il primo momento in cui compare ufficialmente il termine Artificial Intelligence, coniato da John McCarthy, considerato il padre fondatore del campo.
Perché è stato così importante?
Fino ad allora, computer e logica matematica erano visti come strumenti rigidi. L’idea che una macchina potesse simulare capacità cognitive umane – come il ragionamento, l’apprendimento, la comprensione del linguaggio – aprì un nuovo orizzonte di ricerca.
Nasce così una nuova disciplina scientifica, a cavallo tra informatica, filosofia, psicologia e neuroscienze: l’Intelligenza Artificiale.
Piccola Curiosità: Il progetto originale del seminario dichiarava che il problema dell’IA poteva essere risolto “con un gruppo selezionato di scienziati in due mesi”…siamo ancora al lavoro 70 anni dopo!(McCarthy et al. 1955; Russell and Norvig 2016)
Box.2 – Ragionamento probabilistico e reti bayesiane: un alleato per la diagnosi medica
I modelli basati sulla logica bayesiana permettono ai sistemi intelligenti di valutare ipotesi in condizioni di incertezza, proprio come fa un medico di fronte a un caso complesso.
⇒ Un esempio clinico semplificato:
Un paziente si presenta con:
- Febbre
- Tosse secca
- Saturazione SpO₂ = 90%
Sulla base dell’anamnesi e dei dati locali, la probabilità che abbia una polmonite è inizialmente del 20% (probabilità a priori).
Ma se la saturazione di ossigeno scende sotto il 92%, un sistema basato su rete bayesiana aggiorna la probabilità, integrando il nuovo dato. Il risultato? La probabilità a posteriori che il paziente abbia una polmonite sale, ad esempio, al 65%.
Questo tipo di ragionamento, basato su probabilità condizionate, permette al sistema di non ragionare in bianco e nero, ma di valutare gradualmente le ipotesi in funzione dei dati raccolti.
⇒ In pratica:
- I sistemi esperti tradizionali avrebbero detto: Se tosse e febbre, allora polmonite.
- Le reti bayesiane, invece, dicono: Con tosse e febbre, c’è una certa probabilità; ma con saturazione bassa, la probabilità aumenta sensibilmente.
Questo approccio mima più fedelmente il ragionamento clinico reale, dove ogni nuovo dato può rafforzare o indebolire un’ipotesi, senza eliminarne del tutto altre.
Box.3 – Come funzionano davvero le reti neurali profonde?
Le reti neurali profonde sono un po’ come grandi calcolatrici intelligenti, ispirate (alla lontana) al cervello umano.
Immagina una fabbrica a più piani. Ogni piano fa un lavoro diverso su ciò che riceve e poi lo passa al piano successivo. Ecco cosa succede dentro:
- L’ingresso – i dati grezzi Una foto, una frase, un segnale ECG… Tutto viene trasformato in numeri. È come se la macchina “vedesse” usando solo pixel o parole convertite in codici.
- I livelli nascosti – il cervello della rete Qui entrano in gioco i cosiddetti “strati” della rete neurale:
- Ogni neurone virtuale riceve dei numeri
- Li moltiplica per dei pesi, li somma e poi decide se “accendersi” (attivarsi)
- Passa il risultato al neurone successivo
Man mano che l’informazione passa da uno strato all’altro, la rete comincia a riconoscere pattern complessi:
-
- All’inizio: linee, bordi, colori
- Poi: forme, occhi, nasi…
- Alla fine: “questa è la foto di un cane!”
Più strati → più dettagli → più capacità di riconoscere cose complicate
- L’uscita – la risposta Dopo aver elaborato i dati, la rete decide cosa sta “vedendo” o “leggendo” e dà una risposta:
- “Questa è una radiografia normale”
- “Questa parola è scritta in italiano”
Come fa a migliorare?
- Confronta la sua risposta con quella giusta. Ha sbagliato? Bene! (strano a dirsi, ma utile.)
- Calcola l’errore: quanto si è allontanato dalla verità?
- Propaga l’errore all’indietro, strato per strato, per capire quali collegamenti interni hanno contribuito all’errore.
Questo processo si chiama backpropagation (retro-propagazione dell’errore): è come se la rete si chiedesse: “Dove ho sbagliato? Quale calcolo ha pesato troppo o troppo poco?” - Modifica i pesi delle connessioni.
Un po’ come dire: “La prossima volta, darò meno importanza a questa zona dell’immagine… e più importanza a quell’altra.”
Questo processo si ripete migliaia di volte, con tantissimi esempi. Ogni volta la rete aggiusta un pochino i suoi “pesi” (i numeri nelle connessioni), finché impara a riconoscere la polmonite sempre meglio.
Box.4 – Machine Learning vs Deep Learning: l’apprendimento con o senza operatore umano
Machine Learning (ML) tradizionale
Impara dai dati ma ha bisogno dell’intervento umano per decidere quali caratteristiche utilizzare.
Esempio – Come riconoscere un’automobile:
Per insegnare a un modello di ML a riconoscere un’automobile, un umano (vedi Fig.2) deve indicare le caratteristiche salienti:
- Ha quattro ruote?
- Ha una targa?
- Ha un abitacolo chiuso?
Il sistema apprende solo da questi elementi selezionati.
Se un’auto non rispetta pienamente quei criteri (es. vista laterale o coperta), il modello può sbagliare.
Deep Learning (DL)
Usa reti neurali profonde e apprende direttamente dalle immagini o dai dati, senza istruzioni esplicite.
Esempio – Riconoscere un’automobile con il deep learning:
Si forniscono al sistema migliaia di immagini (auto, moto, autobus, biciclette…).
Il modello analizza ogni immagine pixel per pixel e impara da solo le regole visive per riconoscere un’automobile, anche in condizioni variabili (luci, angolazioni, parziale copertura).
Riconosce un’automobile anche senza sapere cosa sia una ruota o un cofano: lo deduce autonomamente.
Box.5 – Cos’è l’Intelligenza Artificiale Generativa?
Immagina un cervello artificiale che ha letto milioni di testi, immagini, conversazioni e perfino referti medici. Non ha emozioni, non capisce come un essere umano, ma ha imparato una cosa potente: prevedere cosa viene dopo.
Esempio: Scriviamo:
“Il paziente presenta febbre, tosse e…”
L’IA generativa continua:
“…dispnea e infiltrati polmonari, suggerendo una possibile polmonite.”
Come fa?
Non “capisce” davvero la polmonite, ma ha visto tantissimi esempi simili. Quindi calcola quale parola o frase è statisticamente più probabile.
Applicazioni in medicina:
- Scrivere bozze di referti clinici
- Generare immagini mediche simulate per l’apprendimento
- Spiegare concetti complessi in modo semplice e veloce
Ma attenzione!
- L’IA non ragiona come un medico
- Può sbagliare se mal addestrata
- Non ha un modello del corpo umano, solo dati e numeri
Una metafora utile:
“L’IA generativa è come uno studente super veloce che ha letto tutti i libri di medicina… ma che non ha mai visitato un paziente vero!”
Serve sempre un medico – cioè voi! – per guidarla e controllarla. L’intelligenza umana resta insostituibile.
Box.6 – Dai neuroni artificiali ai foundation models: cosa è cambiato davvero? (Topol 2019; LeCun, Bengio, and Hinton 2015; Bommasani et al., n.d.)
- Il deep learning (vedi Box.3 e Fig.1) è una tecnica di intelligenza artificiale che usa reti neurali artificiali profonde, cioè strutture fatte di tanti “strati” di nodi matematici (neuroni virtuali) connessi tra loro. Queste reti sono in grado di apprendere pattern complessi di dati, come forme all’interno di una radiografia o caratteristiche linguistiche in un testo.
Per anni, il deep learning è stato utilizzato per compiti molto specifici: riconoscere tumori in immagini, trascrivere la voce in testo, classificare email come spam. - Il salto di scala: i foundation models
Negli ultimi anni, un’evoluzione fondamentale ha portato alla nascita dei cosiddetti foundation models. Si tratta di modelli di deep learning su scala enorme, addestrati su miliardi di dati (testi, immagini, suoni) e progettati per essere generalisti: una sola architettura capace di svolgere moltissimi compiti diversi, anche non previsti inizialmente.
Esempi noti
- GPT (ChatGPT)
- Gemini (Google)
- Claude (Anthropic)
La grande differenza? Mentre un modello classico di deep learning è come un bravo specialista (es. solo per ECG), un “foundation model” è come un “internista digitale”, capace di analizzare molte situazioni, adattandosi a compiti diversi con pochi esempi (parliamo infatti di few-shot o zero-shot learning).
In medicina, questo significa che un unico foundation model può:
- Leggere testi clinici e produrre riassunti
- Analizzare immagini istologiche
- Generare referti o spiegazioni semplificate
- Tradurre linguaggi tecnici per i pazienti
Tuttavia, non capisce davvero ciò che fa: genera output plausibili perché ha visto milioni di esempi simili, non perché ragioni come un medico.
Box.7 – Dai token agli embedding: come le macchine “capiscono”
Tutto ciò che vediamo, diciamo o ascoltiamo può essere trasformato in numeri:
- Testo: la frase “Il paziente presenta dispnea” diventa una sequenza di token ([“Il“, “paziente“, “presenta“, “dispnea“]), ognuno tradotto in vettori numerici.
- Immagine: ogni pixel (un puntino dell’immagine) ha valori numerici RGB. La macchina impara a riconoscere schemi visivi (bordature, ombre…).
- Audio: ogni suono viene convertito in campioni numerici; un modello addestrato può predire il suono successivo in una parola o in una melodia.
Confrontando questi numeri in spazi vettoriali, il sistema può calcolare somiglianze (vedi Box.8). È il principio degli embedding, che consente ad esempio ai vector database di restituire tutte le immagini simili a una radiografia data in input, facilitando analisi comparative su larga scala (vedi anche Fig.3).
Box.8 – Embedding e somiglianza semantica: somiglianze tra oggetti nello spazio vettoriale (Come capisce l’intelligenza artificiale?)
Per un sistema di intelligenza artificiale, ogni oggetto – che sia un cane, un gatto o un martello – può essere rappresentato con una serie di numeri. Questa rappresentazione numerica si chiama embedding.
Ecco come funziona:
- Le immagini vengono trasformate in numeri (vedi Fig.3):
- Due immagini di cani ricevono numeri simili (es. [4, 4.1] e [4, 4])
- Due immagini di felini ricevono anch’esse numeri simili, ma leggermente diversi (es. [3.1, 3.2] e [3, 2])
- Il martello, essendo un oggetto e non un animale, riceve numeri molto diversi (es. [-3, 2])
- Questi numeri diventano punti in uno spazio:
- I cani sono vicini tra loro nello spazio → il sistema li riconosce come simili
- I felini sono vicini tra loro, ma anche relativamente vicini ai cani → sono entrambi animali
- Il martello è lontano da tutti → non ha nulla in comune, né visivamente né semanticamente
- Il sistema può così “capire” le somiglianze senza sapere cos’è un cane, un gatto o un martello:
- Se i punti sono vicini → oggetti simili
- Se sono lontani → oggetti diversi
In sintesi:
L’intelligenza artificiale non comprende il significato come un essere umano. Ma rappresentando ogni oggetto con numeri, può capire quanto due cose sono vicine – e quindi, in un certo senso, simili.
Questo stesso meccanismo viene utilizzato:
- per trovare immagini mediche simili in un archivio.
- per raggruppare concetti nel linguaggio naturale.
- per organizzare conoscenze in sistemi intelligenti.
Box.9 – Prompt Engineering e Chain-of-Thought: far ragionare l’IA come uno studente di medicina
Cos’è il Prompt Engineering?
È l’arte di scrivere le istruzioni giuste per ottenere risposte migliori dall’intelligenza artificiale.
In pratica, non basta “fare una domanda”: bisogna saperla formulare bene per guidare il modello nel modo più utile.
Esempio 1 – Prompt generico:
“Qual è la diagnosi più probabile con febbre, tosse e dispnea?”
Risposta possibile dell’IA:
“Potrebbe trattarsi di polmonite.”
È una risposta corretta, ma senza spiegazione. Un medico in formazione ne ricava poco.
Esempio 2 – Prompt con Chain-of-Thought Prompting:
“Elenca passo dopo passo il ragionamento clinico per arrivare alla diagnosi più probabile in un paziente con febbre, tosse e dispnea.”
Risposta dell’IA (semplificata):
- I sintomi indicano un possibile coinvolgimento dell’apparato respiratorio.
- La febbre suggerisce un processo infettivo.
- La tosse e la dispnea possono indicare una patologia polmonare.
- Un’ipotesi comune in presenza di questi tre sintomi è la polmonite.
“Diagnosi più probabile: polmonite.”
Ora la risposta mostra il ragionamento clinico, come farebbe uno studente che espone il caso durante una discussione in reparto.
Perché è utile in medicina?
- Aiuta a verificare i passaggi logici dell’IA.
- Riduce il rischio di errori.
- Rende l’IA uno strumento di apprendimento, non solo di risposta.
- Permette agli studenti di confrontare il proprio ragionamento con quello del modello.
In sintesi:
Un prompt ben fatto fa la differenza tra una risposta superficiale e un ragionamento clinico approfondito.
Il chain-of-thought prompting è come dire all’IA:
“Mostrami i passaggi. Fammi vedere come ci sei arrivata.”
Bibliografia
- Bommasani, Rishi, Drew A Hudson, Ehsan Adeli Russ Altman, and Simran Arora. n.d. On the Opportunities and Risks of Foundation Models.
- Goodfellow, Ian J., Jonathon Shlens, and Christian Szegedy. 2015. Explaining and Harnessing Adversarial Examples. arXiv
- Hannun, Awni Y., Pranav Rajpurkar, Masoumeh Haghpanahi, Geoffrey H. Tison, Codie Bourn, Mintu P. Turakhia, and Andrew Y. Ng. 2019. Cardiologist-Level Arrhythmia Detection and Classification in Ambulatory Electrocardiograms Using a Deep Neural Network. Nature Medicine 25 (1): 65–69
- Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E Hinton. 2012. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems. Vol. 25. Curran Associates, Inc.
- LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. 2015. Deep Learning. Nature 521 (7553): 436–44
- McCarthy, J, M L Minsky, N Rochester, IBM Corporation, and C E Shannon. 1955. A Proposal For The Dartmouth Summer Research Project On Artificial Intelligence, August
- OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, et al. 2024. GPT-4 Technical Report. arXiv
- Pearl, Judea. 2014. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference. Elsevier
- Russell, Stuart J., and Peter Norvig. 2016. Artificial Intelligence: A Modern Approach. Pearson
- Sahoo, Pranab, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. 2024. A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications. arXiv Preprint arXiv:2402.07927
- Samuel, A. L. 1959. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development 3 (3): 210–29
- Searle, John R. 1980. Minds, Brains, and Programs. Behavioral and Brain Sciences 3 (3): 417–24
- Silver, David, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, et al. 2016. Mastering the Game of Go with Deep Neural Networks and Tree Search. Nature 529 (7587): 484–89
- Topol, Eric. 2019. Deep Medicine: How Artificial Intelligence Can Make Healthcare Human Again. Hachette UK




{kind=link}